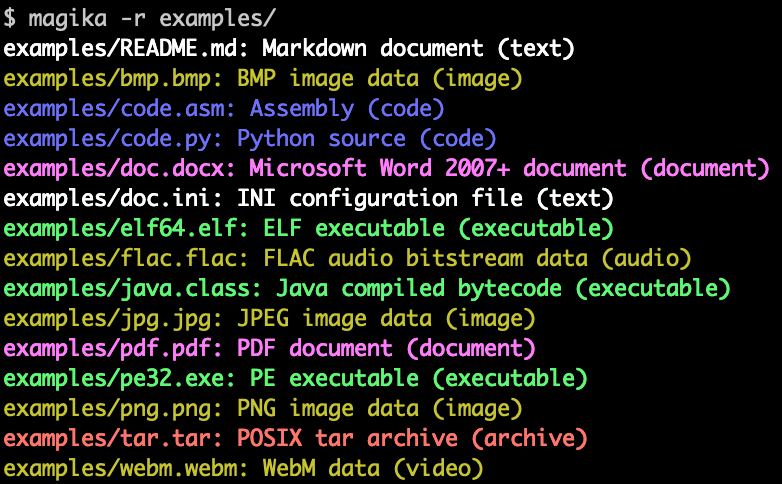
Google Company announced about opening the project code Magika, designed to determine the type of content based on analysis of the data available in the file. Magika can accurately detect the programming languages, compression methods, installation packages, executable code, markup types, audio, video, document and image formats in content. Project-related tools and ready-made machine learning model published licensed under Apache 2.0.
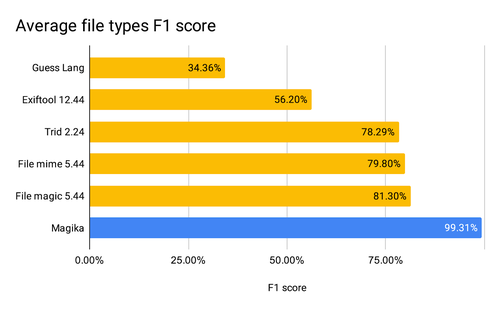
Magika differs from similar projects that determine the MIME type by content by using machine learning methods, high performance and excellent detection accuracy. The model is trained using the framework Keras on 25 million sample files and supports recognition 116 data types with an accuracy of at least 99%. The model is arranged in the format ONNX and is only 1 MB in size. The use of deep machine learning methods made it possible to increase the accuracy of detection by 50% compared to the system previously used by Google based on manually specified rules.
Advertisement
At Google, the system is used to classify files in the Gmail, Drive, Code Insight and Safe Browsing services when performing security checks and compliance with service rules. Work is underway to integrate Magika into the VirusTotal platform as a link for primary file filtering before running specific analyzers. Deployed on Google's infrastructure, Magika can scan several million files per second and several hundred billion files per week. After loading the model, the output generation time is 5-6 ms when testing on a single CPU core. The detection time is almost independent of the file size.
To use Magika in your projects, a command line utility has been prepared, plastic bag for Python and JavaScript library, capable of running in the browser or in projects based on Node.js. The command line interface and API support performing operations in batch mode, i.e. allow you to scan multiple files in one request. There is a mode for recursively scanning the entire contents of a directory and three prediction modes for adjusting error tolerance (high confidence, medium confidence and best guess).
Advertisement
Thanks for reading: