
당신이 젊은 기술 매니아이거나 단순히 PC를 구입하는 일반 구매자라면 특정 프로세서의 사양에 “캐시”가 나열된 것을 보고 그것이 정확히 무엇인지 궁금할 것입니다. 이는 수십년 동안 CPU의 주요 마케팅 포인트였으며, 최근에는 GPU에 대한 논의거리까지 되기도 했습니다.
영어로 “cash”처럼 발음되는 “Cache”(때때로 “$”로 축약되어 표시됨)는 본질적으로 저장 공간의 한 형태입니다. RAM, SSD, 하드 드라이브와 마찬가지로 캐시는 프로세서가 작동할 프로그램 지침과 데이터를 저장하는 역할을 합니다. “그건 중복되는 것 같은데”라고 생각하신다면, 축하드립니다! 그러나 단순한 설명에 기초한 것처럼 중복되는 것은 아닙니다. 이유를 살펴보겠습니다.
Advertisement

초기에는 컴퓨터가 주 메모리를 완전히 사용하여 작업했습니다. 그러나 CPU 성능은 메모리 액세스 대기 시간 개선을 빠르게 앞지르기 시작했습니다. 이는 CPU가 RAM에서 명령과 데이터를 기다리는 데 많은 시간을 소비하기 시작했음을 의미합니다. 분명히 CPU가 대기하는 데 소비하는 시간은 작동하지 않는 시간입니다. 무엇을 해야 할까요? 더 작고 빠른 메모리를 CPU 코어에 훨씬 더 가깝게 배치하십시오. 이 작은 “캐시”는 느린 주 메모리를 기다리지 않고도 자주 사용하는 명령과 데이터를 배고픈 CPU에 전달할 수 있습니다.
메모리 액세스를 위해 로컬 캐시를 사용한다는 아이디어는 실제로 마이크로프로세서가 발명되기 전인 1960년대에 시작되었지만 1980년대까지 가정용 컴퓨터에 적용되지 않았습니다. “캐시”를 정확히 어떻게 정의하느냐에 따라 다르지만 Intel의 80286, Motorola의 68020 및 Intel의 80486 프로세서는 모두 “캐시가 통합된 최초의 PC CPU”라는 제목에 대한 합당한 주장을 가지고 있지만 대부분의 사람들은 486을 CPU 캐시에 대한 현대적 개념을 갖춘 최초의 소비자 칩입니다. 여기에는 현재 L1 캐시라고 불리는 8KB(이후 16KB)의 온칩 캐시가 포함되어 있습니다. 얼마 지나지 않아 Pentium Pro(사진 위)에는 온다이 L1 캐시와 최대 1MB의 L2 캐시를 위한 두 번째 실리콘 다이 온 패키지가 함께 제공되었습니다.
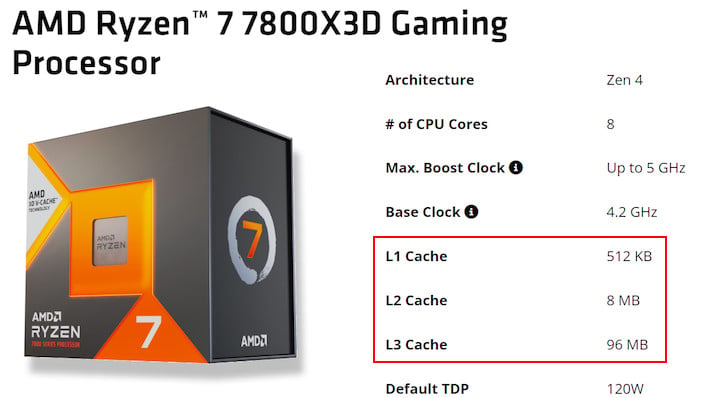
요즘 프로세서에는 일반적으로 프로세서 다이 또는 CPU 패키지의 물리적으로 구별되는 위치에 2~3개의 서로 다른 캐시 “레벨”이 있습니다. 일반적으로 각 CPU 코어 내부에 L1 캐시가 직접 위치합니다. 이는 CPU 명령과 처리할 데이터를 위해 별도의 섹션으로 자주 분할됩니다. L1 캐시는 액세스 속도가 매우 빠르며 필요한 데이터나 명령이 이미 캐시되어 있는 경우 프로세서가 거의 즉시 작업을 재개할 수 있습니다. 단점은 위치 때문에 크기가 매우 작다는 것입니다(보통 96KB 이하).
그런 다음 명령과 데이터 모두에서 공유되는 코어의 기능 단위 외부 또는 가장자리를 따라 L2 캐시가 있게 됩니다. 일부 프로세서 설계에서 L2 캐시는 각 4개 코어 클러스터에서 공유되는 2~4MB의 L2 캐시가 있는 Intel의 현재 “E-코어”와 같이 여러 코어에서도 공유됩니다. L2 캐시는 L1 캐시보다 액세스 속도가 약간 느리지만 Zen 4에서는 전체 메가바이트, Raptor Cove에서는 전체 2MB 정도로 훨씬 더 크다는 단점이 있습니다.

다음으로, 요즘 대부분의 프로세서에는 일반적으로 코어 클러스터 자체 외부에 있는 L3 캐시도 있습니다. 이 L3 캐시는 일반적으로 모든 로컬 CPU 코어에서 공유되지만 오늘날 많은 프로세서에는 각 코어 클러스터에 캐시의 일부가 연결된 분할 L3이 있습니다. 각 “Core Complex Die”(CCD)에는 자체 32MB L3 캐시가 있는 AMD의 Ryzen 프로세서에서 가장 두드러지게 나타납니다. 서로 다른 CCD의 코어는 다른 CCD의 캐시에 액세스할 수 있으며 이는 주 메모리에 액세스하는 것보다 여전히 빠르지만 로컬 캐시를 사용하는 것보다는 상당히 느립니다.
마지막으로 과거의 일부 프로세서에는 L4 캐시가 함께 제공되었습니다. 이는 매우 드물며 일부 프로세서에서만 발견되었습니다. 주로 일부 IBM POWER 제품군 설계와 4세대 및 5세대의 일부 Intel 칩이 있습니다. L4 캐시가 있는 경우 일반적으로 시스템 수준 캐시처럼 기능하여 CPU 코어에 대한 데이터를 캐시할 수 있을 뿐만 아니라 GPU 및 기타 시스템 기능에 대한 데이터도 캐시할 수 있습니다. 일부 초기 유출에서는 Intel의 Meteor Lake에 L4 캐시가 있었을 수도 있지만 현재까지의 Core Ultra 프로세서에는 아직 이 기능이 포함되지 않았음을 암시합니다.
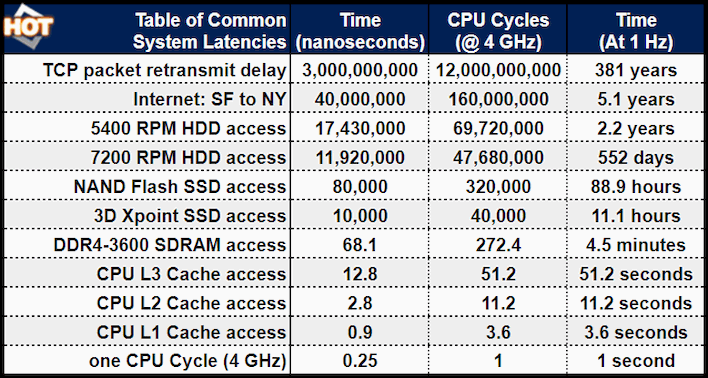
그렇다면 최신 RAM은 매우 빠르죠? DDR5를 사용하면 핀당 속도가 7.5Gbps에 달합니다. 현대에 CPU 캐시의 의미는 무엇입니까? 우선, CPU 캐시는 그보다 훨씬 더 빠릅니다. 그러나 더욱이 문제는 대기 시간이 매우 짧은 메인 메모리가 있더라도 여전히 CPU의 L3 캐시보다 액세스 시간이 5배 이상 느리고 L3 자체도 CPU의 L3 캐시보다 거의 5배 느리다는 것입니다. L2. 흥미로운 비교를 보려면 위의 표를 확인하십시오.
대부분의 CPU 명령은 단일 주기로 완료되지 않지만 L1 캐시에 대한 액세스도 완료하는 데 약 4주기가 걸립니다. 데이터가 캐시에 없으면 메인 메모리로 이동해야 하며, 대기하면서 270개 이상의 CPU 사이클을 소모하게 됩니다. 데이터가 RAM에 없으면 시간이 좀 걸릴 것입니다. 다른 작업에 이미 데이터가 준비되어 있으면 기다리는 동안 해당 코어의 다른 작업으로 전환하는 것이 좋습니다. 그런데 이 개념은 멀티 태스킹의 기초입니다.
차트 상단에 있는 큰 숫자의 범위를 이해하는 데 어려움을 겪고 있다면 마지막 열을 확인하세요. 이는 동일한 프로세서가 초당 40억 사이클이 아닌 초당 1사이클로 실행되는 경우 각 작업에 소요되는 시간을 나타냅니다. 이로 인해 L2 캐시 액세스에 필요한 시간이 11.2초로 변경됩니다. 이는 SSD 액세스에 필요한 거의 90시간에 비해 여전히 꽤 빠른 것 같습니다.
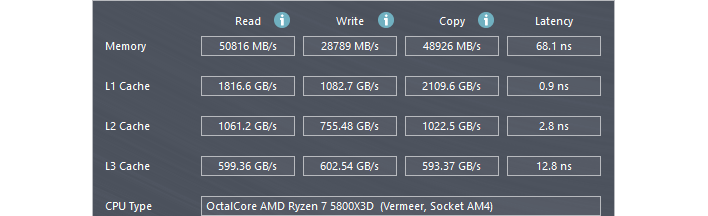
하지만 고려해야 할 대기 시간 이상의 것이 있습니다. 위 내용은 작성자 PC의 AIDA64 캐시 및 메모리 벤치마크 결과에서 잘라낸 것입니다. 보시다시피 시스템의 3600MT/s DDR4 메모리에서 읽을 때의 전송 속도는 초당 거의 51GB입니다. L3 캐시에서 읽을 때 초당 거의 600GB에 달하는 것과 비교해 보면 큰 캐시가 성능에 얼마나 큰 차이를 가져올 수 있는지 알 수 있습니다.
이는 최근 몇 년 동안 3D V-Cache를 지원하는 AMD의 “X3D” 프로세서를 통해 가장 눈에 띄게 입증되었습니다. AMD는 Zen 3 “Vermeer” 및 Zen 4 “Raphael” 프로세서에 추가 실리콘 조각을 수직으로 쌓아 하나의 코어 칩렛(CCD)에 사용할 수 있는 L3 캐시를 3배로 늘릴 수 있었습니다. 이를 위해서는 표준 모델에 비해 CPU 클럭 속도를 어느 정도 줄여야 하지만 여전히 특정 애플리케이션, 특히 3D 게임의 성능이 크게 향상됩니다. 왜 그런 겁니까?

결론적으로 아이러니하게도 비디오 게임은 컴퓨터에서 실행할 수 있는 가장 까다로운 작업 부하 중 하나라는 것입니다. 게임은 새로운 프로그램 조각과 해당 프로그램 조각에서 처리할 새로운 데이터 비트를 지속적으로 로드합니다. 최신 3D 게임, 특히 네트워크로 연결된 3D 게임에서는 엄청나게 다양한 일이 발생하기 때문에 CPU 캐시가 오버플로되어 앱이 나가서 메인 메모리에 훨씬 더 자주 도달하게 되는 경우가 많습니다. Ryzen의 이미 큰 L3 캐시 크기를 3배로 늘리면 그럴 가능성이 훨씬 줄어들어 프로세서가 작업에 더 많은 시간을 할애하고 데이터나 코드를 기다리는 시간을 줄일 수 있습니다.
분명히 말하면, 프로세서 캐싱에 대해 배울 내용이 훨씬 더 많습니다. 이 기사는 캐시 개념에 대한 기본적인 설명일 뿐이며 캐시를 구현할 수 있는 다양한 방법이나 프로세서 캐시의 다양한 유형을 설명하는 장황한 내용은 다루지 않습니다. 궁극적으로 소비자로서 알아야 할 것은 캐시 크기가 애플리케이션 성능에 엄청난 차이를 만들 수 있다는 것입니다. CPU 코어 수와는 달리 많을수록 항상 더 좋습니다. 그러나 많을수록 항상 더 좋다면 모든 프로세서를 모두 만드는 것은 어떨까요? 엄청난 양의 캐시를 가지고 있나요? 왜 전체 RAM을 CPU에 두지 않습니까? 잘…
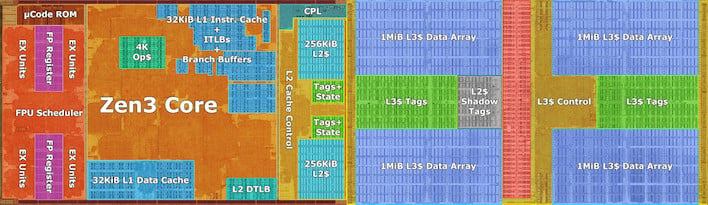
단일 Zen 3 CPU 코어에 대한 이 주석이 달린 다이샷은 최신 프로세서 코어가 캐시 전용으로 얼마나 많은지 보여줍니다. 코어의 거의 파란색인 오른쪽 절반을 무시하더라도 여전히 32+32K L1 캐시와 512K L2 캐시를 위해 할당된 CPU 코어의 상당 부분이 있으며, 그 다음에는 거대한 4MB의 L3 캐시와 모든 캐시가 있습니다. 관련 제어 하드웨어의.
간단히 말해서, SRAM(캐시에 사용되는 메모리)은 매우 크고, 이를 다이에 많이 넣으면 다이 영역을 매우 빠르게 먹어치웁니다. 이로 인해 프로세서를 매우 빠르게 제조하는 데 엄청나게 비용이 많이 듭니다. 이것이 바로 AMD가 3D V-Cache를 고안한 이유입니다. 점진적으로 더 큰 캐시를 추가하기 위해 연속적으로 더 큰 칩을 만드는 대신 회사는 별도의 캐시 칩렛을 제작하여 기존 프로세서에 스테이플링할 수 있습니다.
우리는 여기서 잠시 AMD에 초점을 맞췄지만 인텔이 프로세서 캐시의 이점을 모르는 것은 아닙니다. Intel은 L4 캐시를 온/오프로 실험해온 회사인데 Golden Cove(Alder Lake의 P-코어 아키텍처)와 Raptor Cove(Raptor Lake의 P-코어 아키텍처) 간의 가장 큰 변화는 63% 증가입니다. P-코어당 사용 가능한 L2 캐시의 양, E-코어는 L2 캐시를 완전히 두 배로 늘립니다. Intel의 12세대와 13세대 Core CPU 사이에는 다른 아키텍처 차이가 많지 않지만 Raptor Lake는 대부분의 애플리케이션, 특히 게임에서 Alder Lake를 결정적으로 압도합니다. 이제 그 이유를 아실 겁니다.
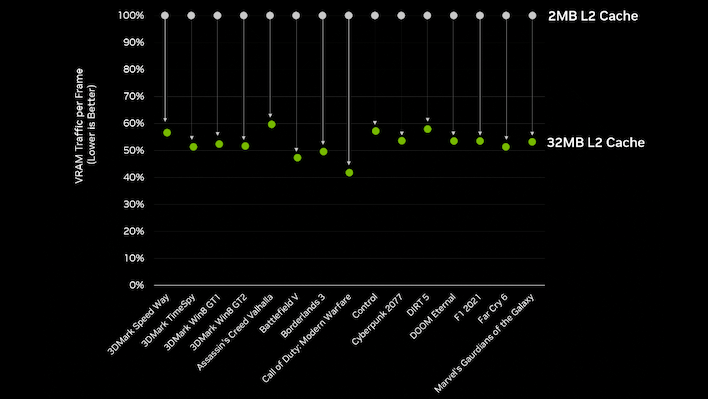
캐시는 그래픽에서도 중요해지기 시작했습니다. AMD의 RDNA 2 그래픽 프로세서 제품군인 Radeon RX 6000 시리즈는 경쟁사 NVIDIA의 “Ampere” GPU에 비해 상대적으로 부족한 메모리 대역폭을 보완하기 위해 대규모 “무한대 캐시”를 사용했습니다. NVIDIA는 이전 세대와 비교하여 해당 GPU의 메모리 버스 폭을 줄인 것을 설명하기 위해 Ada Lovelace 아키텍처의 L2 캐시 크기를 근본적으로 (8배) 늘렸기 때문에 이것이 좋은 아이디어라고 분명히 생각했습니다. 우리는 캐싱이 앞으로도 GPU 설계에서 중요한 요소가 될 것으로 예상할 수 있으며, NPU도 곧 자체 캐시 개발을 시작할 것으로 예상됩니다.
이 설명이 어떤 식으로든 도움이 되었거나, 추가 질문이 있거나, 우리가 실수한 부분에 대해 정정하고 싶은 경우 알려주시기 바랍니다. 또한 이와 같은 더 많은 설명 콘텐츠를 보고 싶다면 댓글을 남겨주세요.