「Gemini モデルの作成に使用されたのと同じ研究とテクノロジーに基づいて構築された」Google の新しい軽量 Gemma LLM は、NVIDIA GPU を搭載したローカル PC ハードウェア上でネイティブに動作するように設計されています。
Google の新しい Gemma AI は軽量で、AI PC 上でネイティブに実行されます (画像クレジット: Google)。
Advertisement
ギャラリーを見る – 2 枚の画像
Gemma 2B と Gemma 7B は、サードパーティの AI アプリケーションで使用するために、どちらも Google DeepMind によって開発されており、Google によれば、各オープン モデルは、GeForce RTX 搭載ラップトップで実行しながら、「主要なベンチマークで大幅に大型のモデル」を上回ることができます。またはパソコン。
Gemma の事前トレーニング済みモデルは、安全かつ信頼できるように設計されており、 NVIDIA の追加 モデルはオープンソースの NVIDIA TensorRT-LLM ライブラリで実行するように最適化されており、AI PC で利用可能な 1 億以上の NVIDIA RTX GPU によって高速化されています。 Gemma は JAX および PyTorch 上でも実行できます。
さらに、Gemma はクラウド内の NVIDIA GPU でも実行されます。 ただし、目標は何百万もの PC やラップトップからアクセスできる軽量のスタンドアロン AI モデルのようです。 NVIDIA AI Playground を介してブラウザーからさまざまな質問をして、Gemma 2B および Gemma 7B を直接テストできます。
Advertisement
NVIDIA はまた、Gemma が新しい Chat with RTX プラットフォームに登場することを確認しました。これは、TensorRT-LLM ソフトウェアを実行する RTX 搭載 Windows PC 上でネイティブに実行される AI 搭載チャットボットです。 開発者は、Google を使用して Gemma モデルにもアクセスできます。 ハブのセットアップ トレーニングと展開をカバーするクイック スタート ガイドが含まれています。
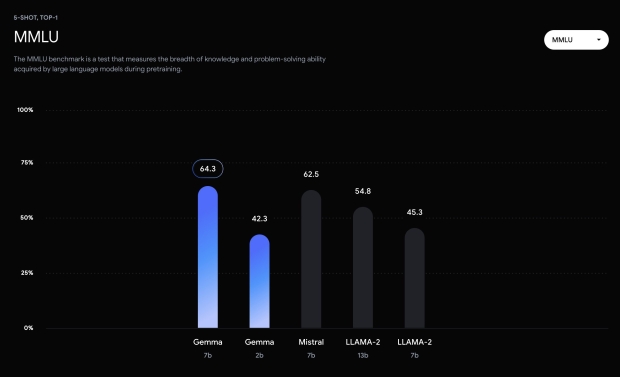
このハブには、問題解決において Gemma 7B が LLAMA-2 7B および 13B より優れていることを示す MMLU ベンチマーク結果も含まれています。 Gemma について詳しく知りたい方は、 詳細な技術レポート モデルのアーキテクチャ、トレーニング、ベンチマーク結果については Google から提供されています。
Googleは「ベンチマークタスクにおける最先端のパフォーマンス測定を超えて、コミュニティからどのような新しいユースケースが生まれ、この分野を一緒に前進させていくことでどのような新機能が生まれるのかを楽しみにしている」と書いている。 「研究者が Gemma を使用して幅広い研究を加速できることを期待しており、開発者が有益な新しいアプリケーション、ユーザー エクスペリエンス、その他の機能を作成できることを願っています。」